


 English
English
provit ist ein Werkzeug zur Annotation und Dokumentation von Daten und ihrer Herkunft (Provenienz). Es bietet verschiedene Funktionen zum Erstellen und Abrufen von Provenienzinformationen für in Dateien gespeicherte Daten. Die Verfolgung von Quellen, Änderungen und Zusammenführungen ermöglicht es dem Benutzer, ein Protokoll aller Änderungen zu führen. Dies ist besonders nützlich für Datensätze, auf die regelmäßig und durch mehrere Personen zugegriffen wird oder die Teil eines lang laufenden Workflows sind (z.B. für eine wissenschaftliche Arbeit). Darüber hinaus können Provenienzdaten, die neben den Daten in einem Archiv gespeichert sind, anderen helfen, Qualität, Wert und Aktualität der Daten und damit des durchlaufenen Forschungsprozesses zu erkennen. Einer der Entwickler von provit, Florian Rämisch, hat mit uns über die Software und deren Anwendung gesprochen.
Idee und Anforderungen
Während unserer datenbasierten Forschung zur Videospielkultur im von der DFG finanzierten Projekt diggr haben wir eine Vielzahl von heterogenen Datenquellen erschlossen. Zur Beantwortung unserer Forschungsfragen war es notwendig, die Informationen und Inhalte dieser Quellen auf verschiedenen Ebenen zu vereinen, anzureichern und neu zusammenzustellen. Diese Prozesse waren z.T. zeitintensiv, erforderten Bearbeitung durch verschiedene Menschen und Programme. Anfang 2018 begannen wir nach einer Möglichkeit zu suchen, diese Bearbeitungsschritte strukturiert und nachvollziehbar zu dokumentieren. Es sollte also zu jedem Forschungsdatensatz den wir erstellt hatten jederzeit nachvollziehbar sein:
- Wie aktuell sind die zugrunde liegenden Rohdaten?
- Wann und wie wurden diese akquiriert?
- Welche weiteren Bearbeitungsschritte wurden wann und in welcher Reihenfolge durchgeführt?
Provenance Management Systeme sind nichts neues, es gab bereits einige Tools mit unterschiedlichen Ausrichtungen. Unseren Anforderungen entsprach allerdings keines. Wir haben ein System mit folgenden Eigenschaften gesucht:
- Keine zentrale Infrastruktur/Datenbank,
- Informationsspeicherung möglichst dateibasiert,
- Basierend auf einem etablierten und interoperablen Datenformat,
- Möglichkeit der einfachen Integration in bestehende ETL-Pipeline,
- Nutzbarkeit durch Forscher*innen ohne Programmierkenntnisse.
Das von uns entwickelte Tool provit ist ein erster Versuch diesen Anforderungen so gut es geht gerecht zu werden und diese auf ihre Praxistauglichkeit zu testen.
Zielgruppe
Die Zielgruppe von provit sind Forscher*innen und wissenschaftliche Softwareentwickler*innen, die allein oder in kleinen Gruppen über längere Zeiträume mit Daten arbeiten. Daten, die insbesondere viele Zwischenbearbeitungen (Bereinigung, Zusammenführung, etc.) erfordern, bevor sie zur Beantwortung von Forschungsfragen genutzt werden können.
Funktionsweise
Für Forscher*innen
Forscher*innen können mithilfe einer browserbasierten grafischen Benutzeroberfläche oder per Kommandozeile mit provit interagieren. Die grafische Benutzeroberfläche ermöglicht es auch auf einfache Weise vorhandene Provenance-Informationen von Dateien anzuschauen und zu erkunden, sowie weitere Punkte hinzuzufügen.
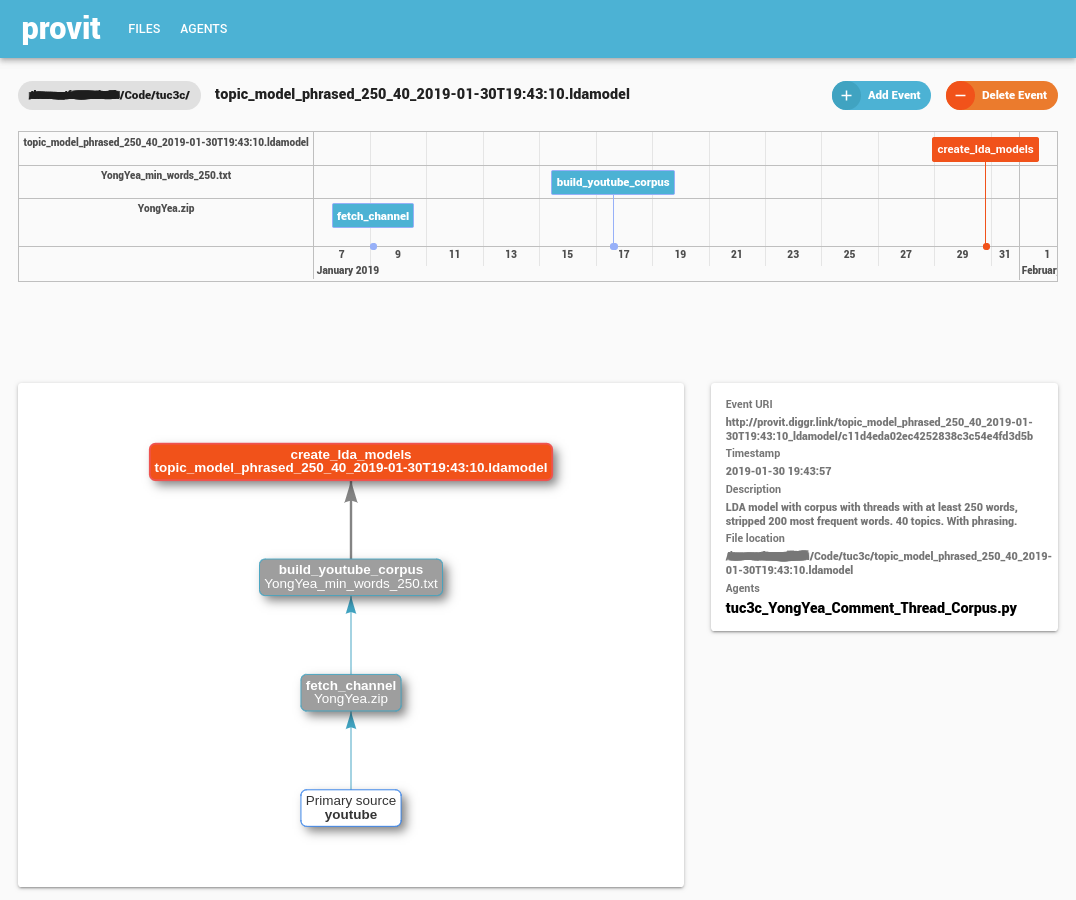
Die Browserschnittstelle von provit
Für Entwickler*innen
Entwickler*innen können provit sehr leicht in ihre bestehenden pythonbasierten ETL-Pipelines integrieren. Dafür kann man aus dem Python Package Index (also direkt per pip install provit) das Programm installieren und dann entsprechend der Anleitung benutzen.
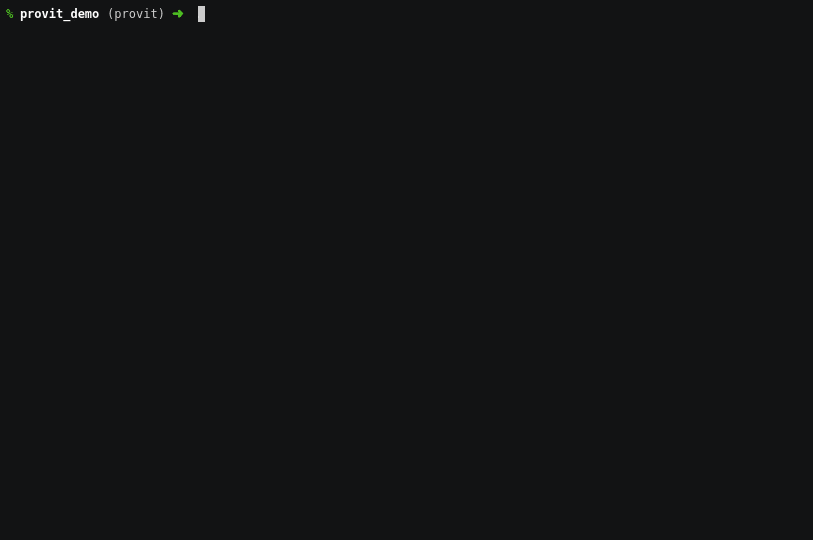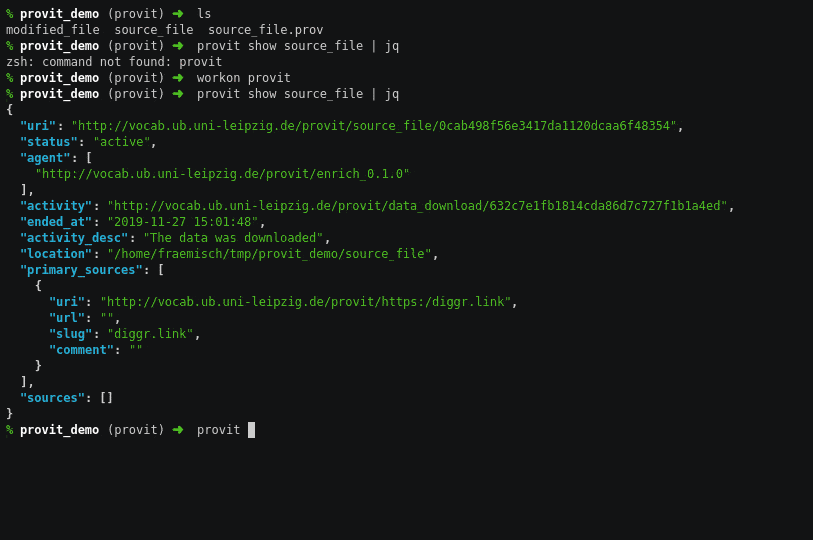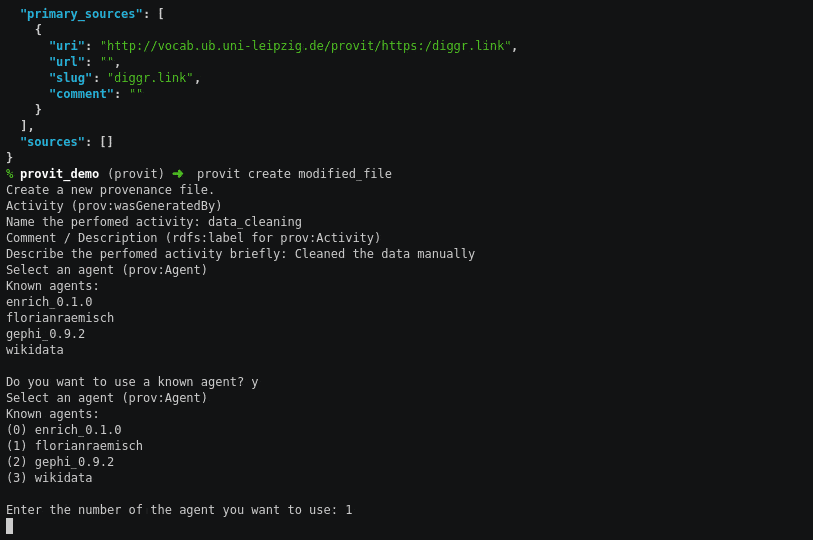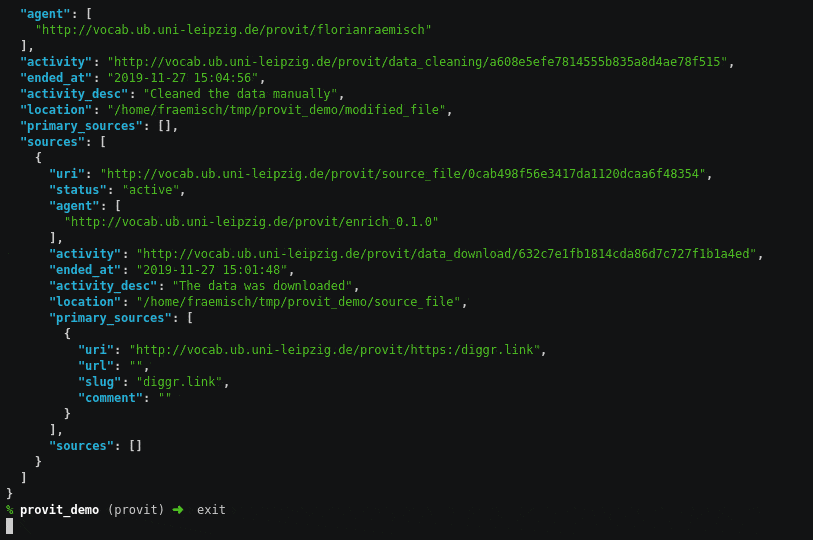
provit auf der Kommandozeile
Weitere Entwicklungen
Unser Forschungsprojekt endet im Juli 2020, daher wird die Weiterentwicklung, sofern sich keine Maintainer*in findet, vermutlich zu diesem Zeitpunkt eingestellt.
Danksagung
Provit wurde im Rahmen des DFG-Forschungsprojektes „Datenbasierte Spurensuche globaler Einflüsse japanischer Videospielkultur“ (DFG Projektnummer 316697723) an der Universitätsbibliothek Leipzig in Kooperation mit der Japanologie des Ostasiatischen Instituts der Universität Leipzig entwickelt.
Autor: Florian Rämisch
Repository: https://github.com/diggr/provit